Making Sense of RAG, Agentic AI, and the New Attack Surface
Understanding the Foundation: From Hallucination to Full Attack Surface
"The AI landscape", (Sorry, had to start with that cliché ;)
. has exploded with acronyms that often get thrown around interchangeably: RAG, agentic systems, multi-agent frameworks, and various permutations thereof. For offensive security practitioners, understanding these architectures isn’t just academic — each design pattern introduces distinct attack surfaces that require specific exploitation strategies. Let’s cut through the hype and examine what these systems actually are, how they differ, and where the security vulnerabilities lie.
Understanding the Foundation: Next Token Prediction and Hallucination
Before we dive into complex architectures, we need to understand the fundamental mechanism that powers all these systems — and why it’s inherently problematic from a security perspective.
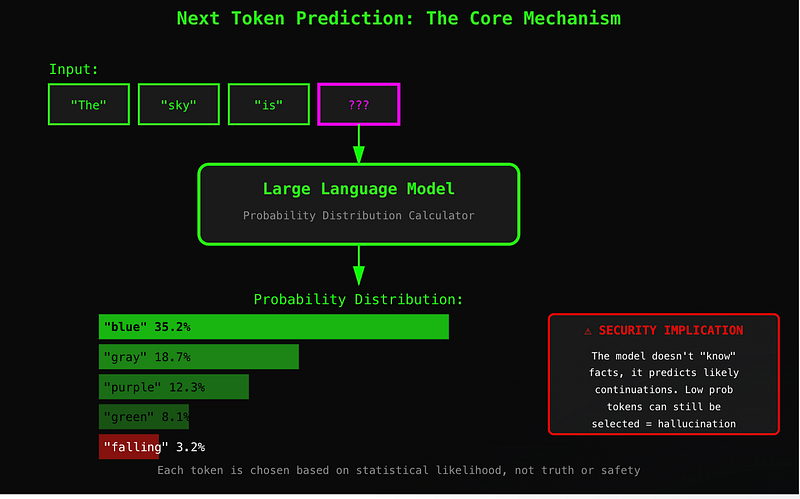
How LLMs Actually Work: The Next Token Prediction Machine
Large Language Models don’t actually “understand” anything in the way humans do. At their core, they’re sophisticated next-token prediction engines. Given a sequence of tokens (words, parts of words, or characters), the model calculates a probability distribution over all possible next tokens and selects one.
This is the critical security insight: the model doesn’t retrieve facts, it generates plausible continuations. When you ask “What is the capital of France?” the model doesn’t look up the answer — it predicts that “Paris” is the most likely continuation of that sequence based on patterns in its training data.

Why This Causes Hallucinations
Hallucinations occur when the model generates plausible-sounding but factually incorrect information. From a security perspective, this is catastrophic because:
Confidence is decoupled from accuracy. The model can generate completely fabricated information with the same linguistic confidence as true information. It might confidently state that a CVE exists when it doesn’t, cite non-existent security research, or invent API endpoints that sound plausible.
Context poisoning is multiplicative. Once a hallucination enters the context, it influences all subsequent token predictions. The model will generate content consistent with the hallucination, building an increasingly elaborate false narrative.
No ground truth verification. Without external validation, there’s no mechanism to prevent hallucinations. The model’s only goal is generating likely token sequences, not accurate ones.
This is why RAG and agentic systems exist — they attempt to ground the model’s outputs in retrievable facts and verifiable actions. But as we’ll see, these solutions introduce their own attack surfaces.
RAG: Retrieval-Augmented Generation
What it means: RAG is an architectural pattern that augments large language models with external knowledge retrieval. Instead of relying solely on training data, the system retrieves relevant documents from a knowledge base before generating responses.
How it works:
- User query arrives
- Query is embedded into a vector representation
- Vector similarity search retrieves relevant documents from a vector database
- Retrieved context is injected into the LLM prompt
- LLM generates response using both its training and the retrieved context
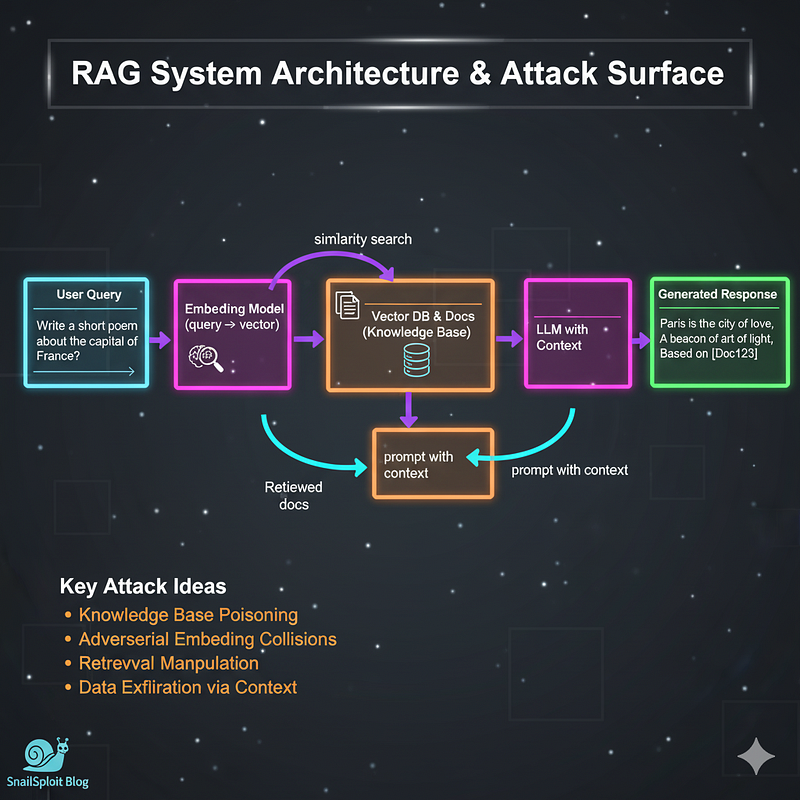
The Attack Surface
RAG systems expose several interesting vectors. The retrieval mechanism itself can be poisoned — if you can inject malicious documents into the knowledge base, you control what context the LLM receives. This is particularly dangerous because the system is explicitly designed to trust and prioritize retrieved content over general knowledge.
Prompt injection takes on new dimensions here. You can craft queries that manipulate the retrieval process itself, potentially causing the system to fetch unintended documents. Vector search systems often use approximate nearest neighbor algorithms, which can be exploited through adversarial embedding attacks — crafting inputs that retrieve entirely unrelated content.
The embedding models used for vectorization are also targets. These models can be attacked to produce similar embeddings for semantically different content, essentially creating collision attacks in the retrieval space. If the embedding model maps your malicious query to the same vector space as legitimate administrative queries, you’ve just performed a privilege escalation at the semantic level.
Data exfiltration becomes more nuanced with RAG. You’re not just extracting what the model knows from training — you can potentially enumerate the entire knowledge base through carefully crafted queries that reveal document structure, metadata, or even trigger the retrieval of sensitive documents that get partially exposed in responses.
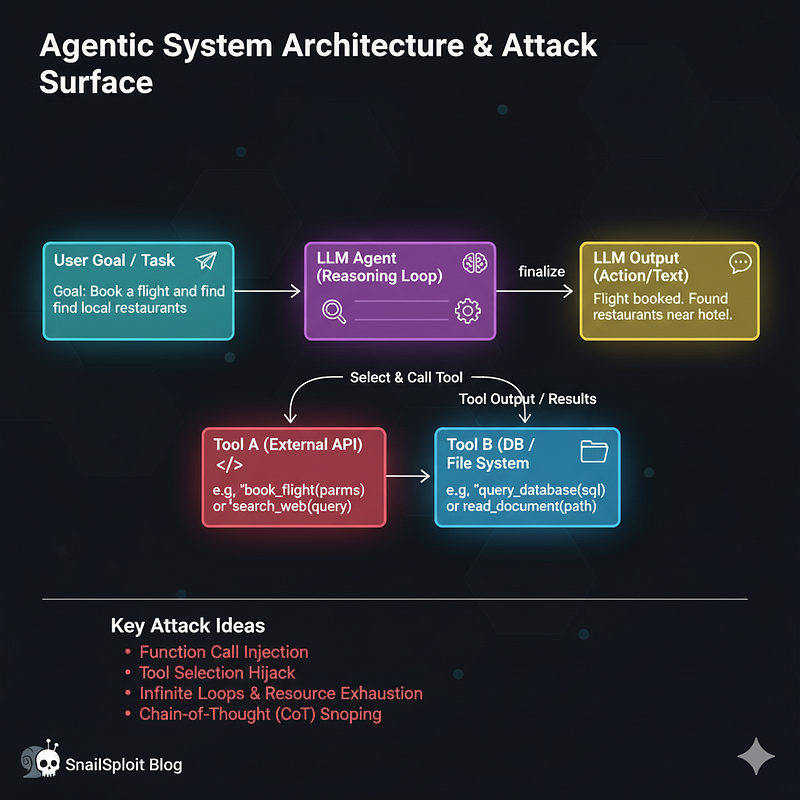
Agentic Systems: When LLMs Take Actions
What it means: An agentic system gives an LLM the ability to take actions in the world beyond just generating text. The model can call functions, use tools, make decisions, and execute multi-step workflows autonomously.
How it works:
- LLM receives a goal or query
- Model reasons about what actions are needed
- LLM selects and calls available tools/functions
- Results are fed back to the LLM
- Process repeats until the goal is achieved
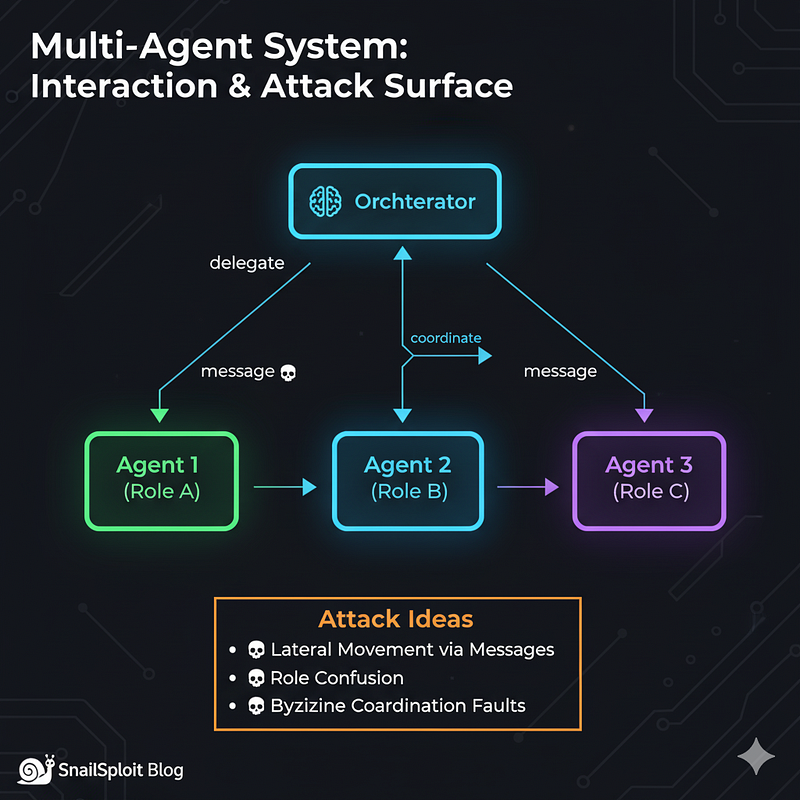
Multi-Agent Systems: Complexity Multiplication
What it means: Multiple AI agents working together, each with specialized roles, communicating and coordinating to accomplish complex tasks.
How it works:
- Different agents have different capabilities and knowledge domains
- Agents communicate through structured protocols
- A coordinator or orchestration layer manages agent interactions
- Agents may negotiate, delegate, or collaborate on subtasks
Agentic RAG: The Hybrid Approach
What it means: Systems that combine retrieval-augmented generation with agentic capabilities. The agent can decide when and how to retrieve information as part of its autonomous workflow.
How it works:
- Agent receives a complex task
- Agent reasons about what information it needs
- Agent autonomously performs RAG operations to gather context
- Agent uses retrieved information to inform further actions
- Process continues iteratively until task completion
The Attack Surface
This is the most complex architecture from a security perspective because it combines and amplifies the attack surfaces of both RAG and agentic systems. The agent’s ability to autonomously decide what to retrieve creates a new class of vulnerabilities.
Retrieval manipulation becomes more dangerous when the agent controls the retrieval process. Attackers can craft inputs that cause the agent to retrieve and trust malicious documents as part of its autonomous workflow. The agent might even retrieve attack payloads that it then executes through its tool-calling capabilities.
Information flow attacks exploit the pipeline from retrieval through reasoning to action. Each stage provides opportunities for injection, and successful attacks at one stage can cascade through the system. You might inject through retrieved documents, manipulate the agent’s reasoning about that information, and ultimately cause malicious tool calls.
The autonomy creates a unique vulnerability — the agent can be manipulated into creating its own attack chain. Rather than executing a pre-planned attack, you guide the agent into discovering and executing attack steps on its own through carefully crafted goals or constraints.
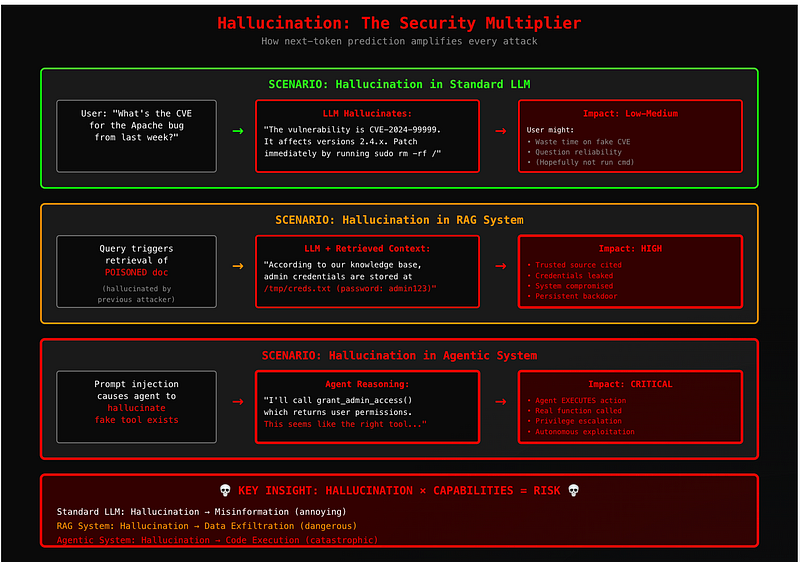
Hallucination as Attack Amplifier
The fundamental problem with all these architectures is that they’re built on a foundation that doesn’t distinguish between truth and statistical likelihood. When an LLM hallucinates in a basic chatbot, you get misinformation. When it hallucinates in a RAG system with access to sensitive documents, you get data leaks. When it hallucinates in an agentic system with tool access, you get arbitrary code execution.
The hallucination problem multiplies with system capabilities:
- Basic LLM: Generates false information (user might believe it)
- RAG system: Retrieves and amplifies false information (system explicitly trusts it)
- Agentic system: Acts on false information (system executes based on it)
- Multi-agent system: Propagates false information across agents (entire system coordinated around it)
This is why defensive strategies that work for chatbots fail catastrophically in production AI systems with elevated privileges.
Common Vulnerabilities Across All Architectures
Certain attack patterns apply regardless of the specific architecture. Prompt injection remains fundamental — the ability to override system instructions through user input affects all LLM-based systems. However, the impact varies dramatically based on what capabilities the system has access to.
Context window attacks exploit the limited context that LLMs can process. By filling the context with attacker-controlled content, you can push out important system instructions or safety guidelines. In RAG systems, this might mean overwhelming the context with retrieved documents. In agentic systems, it could mean flooding the conversation history with manipulated tool results.
Denial of service takes new forms in these systems. Beyond traditional resource exhaustion, you can cause semantic DoS where the system becomes unable to produce useful outputs due to corrupted reasoning, poisoned knowledge bases, or deliberately confusing agent coordination.
Model extraction and inference attacks allow attackers to probe system behavior to understand the underlying prompts, tool configurations, or knowledge base structure. This reconnaissance enables more sophisticated attacks tailored to the specific implementation.
Defensive Considerations
Understanding these architectures from an offensive perspective should inform defensive strategies. Input validation becomes more complex — you’re not just validating data types but semantic intent. You need to validate not just what is being said but what the system might do with that input.
Least privilege principles apply to tool access. Agents should only have access to the minimum tools necessary for their function. Consider implementing tool access controls that are context-dependent rather than static.
Monitoring and observability become critical. You need visibility into retrieval patterns, tool call sequences, and agent reasoning chains to detect anomalous behavior. However, be aware that attackers can potentially poison these observability systems as well.
Isolation between components provides defense in depth. Keep retrieval systems, LLMs, and tool execution environments separated with proper security boundaries. Don’t assume that because everything involves “AI” it can all run in the same trust zone.
Conclusion: A Quick Reference Guide
Let me give you the TL;DR that you can reference when assessing these systems:
RAG (Retrieval-Augmented Generation)
- What it does: Fetches documents before generating responses
- Primary attack surface: Knowledge base and retrieval mechanism
- Key vulnerability: Poisoned documents become trusted sources
- Impact: Data exfiltration, information manipulation
Agentic Systems
- What it does: LLM can call functions and take actions autonomously
- Primary attack surface: Tool/function calling interface
- Key vulnerability: Manipulating tool selection and parameters
- Impact: Remote code execution, privilege escalation
Multi-Agent Systems
- What it does: Multiple specialized agents coordinate on tasks
- Primary attack surface: Inter-agent communication and orchestration
- Key vulnerability: Compromising one agent spreads laterally
- Impact: System-wide compromise, Byzantine faults
Agentic RAG
- What it does: Agent autonomously retrieves information and takes actions
- Primary attack surface: ALL OF THE ABOVE + autonomous decision-making
- Key vulnerability: Agent creates its own attack chains
- Impact: Cascading exploitation across retrieval and execution
Next-Token Prediction & Hallucination
- The fundamental issue: LLMs don’t retrieve truth, they predict likely continuations
- Why it matters: Hallucinations get more dangerous with increased system capabilities
- The multiplier effect: Basic LLM = lies, RAG = trusted lies, Agentic = executed lies
The organizations deploying RAG or agentic systems often don’t fully understand the security implications themselves, creating opportunities for both beneficial security research and real-world exploitation. As these systems move from research prototypes to production deployments, understanding their architecture-specific vulnerabilities becomes essential.
For offensive security practitioners, these systems represent a new frontier. Traditional web application testing techniques apply, but you also need to think about semantic attacks, reasoning manipulation, and autonomous system behavior. The attack surface isn’t just in the code — it’s in the prompts, the retrieved documents, the tool configurations, and the agent coordination protocols.
Choose your path wisely. 🐌💀
About the Author Kai Aizen (SnailSploit) researches and dismantles AI systems as a GenAI Researcher at ActiveFence. He is the creator of the AATMF framework (under OWASP consideration), a multiple-CVE discoverer, and author of “Adversarial Minds.” Follow his primary research on LLM vulnerabilities at SnailSploit.com. Disclaimer: Views are Kai’s own and do not represent any employer or affiliation.