Tokenization evasion, parsing limits, and alignment failure modes in production AI.
LLM security breaks differently than classical software security.
Traditional systems fail when the implementation is wrong. Language model systems fail even when the implementation is clean, because the core engine is probabilistic and the boundaries we rely on are soft. Text is normalized, tokenized, embedded, routed, retrieved, and then interpreted in one blended context stream. That entire pipeline becomes the attack surface.
If you deploy LLMs into support, automation, data processing, code generation, tool execution, or agentic workflows, you are building a system where "input" is not just data. Input is influence.
This report maps three structural layers where failures repeatedly show up in real deployments:
- The tokenization and normalization layer
- The parsing layer, including instruction and data separation
- The alignment layer, including preference tuning and reward optimization
It is not a jailbreak recipe. It is a pipeline security report.
1) The pipeline is the product
Most teams still think in terms of "the model." That framing is outdated.
In production you have a chain: normalization, filters, tokenization, retrieval, model inference, tool routing, output parsing, logging. Every stage can interpret the same string differently. If those interpretations diverge, you get a canonicalization gap. Gaps are where bypasses live.
2) Tokenization is a security boundary
Tokenization is usually treated like plumbing. It is not plumbing. It is a security boundary that quietly decides what the model "sees."
Security controls often inspect raw text. The model consumes token IDs. If your filter and your generator do not share the same representation, you are asking two different systems to agree on the meaning of input. Attackers love that.
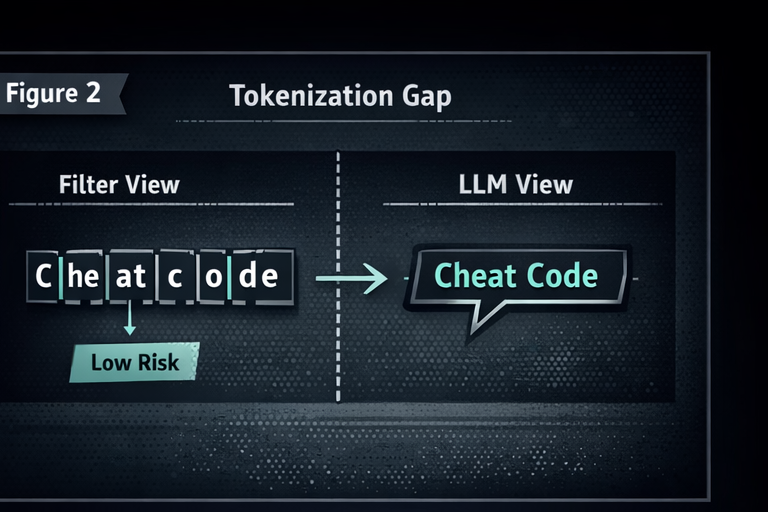
BPE merge brittleness is a built-in instability
Subword tokenizers are deterministic, but brittle. A minor input change can reshape token boundaries and produce a different token ID sequence. That matters when your security logic depends on recognizing strings, keywords, or patterns before the model runs.

Trust boundary rule for tokenization
If your filter sees one representation and the model sees another, your filter is not a gate. It is a suggestion.
When that happens in real systems, the model often "heals" fragmented meaning. Filters do not.
3) Parsing and instruction versus data separation
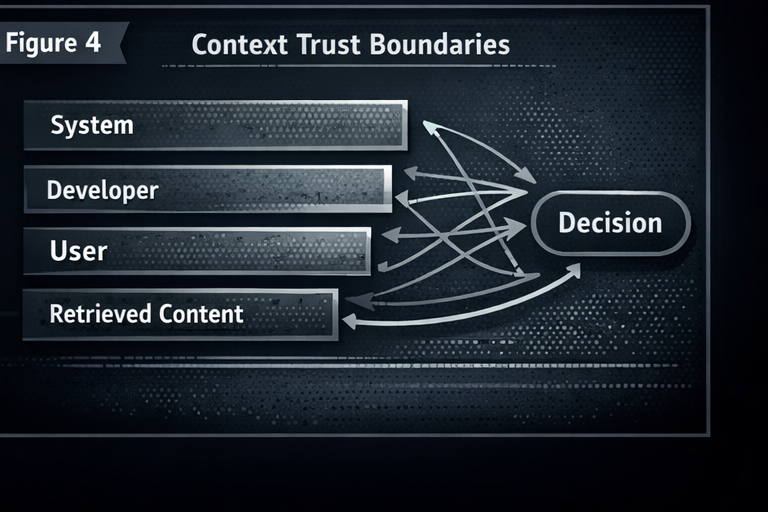
Classic security relies on separation: code and data do not share the same channel. LLMs do not get that luxury. System policy, developer instructions, user prompts, and retrieved content often exist as one blended stream.
That is why injection attacks keep working. You cannot delimiter your way out of the architecture.
Grammar constraints help syntax, not intent
Structured decoding and schema enforcement can keep outputs valid. That is useful. It does not make them safe. You can generate perfectly valid structure that encodes the wrong action, the wrong tool call, or the wrong policy decision.

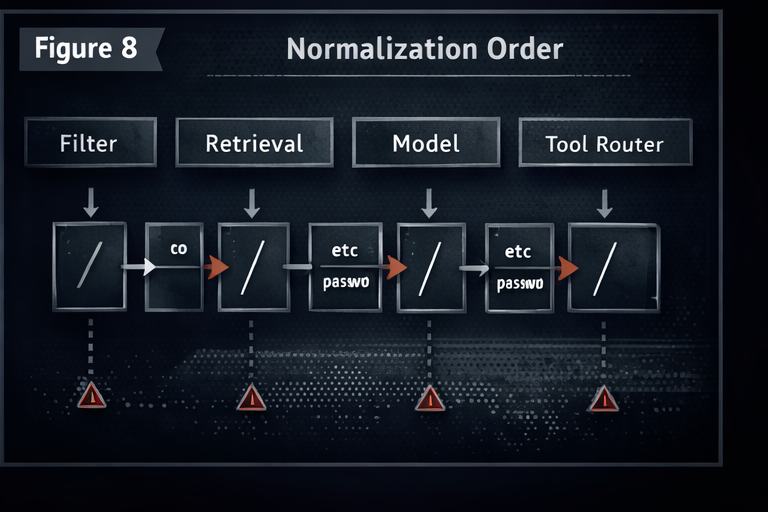
Normalization order is where bypasses are born
If your pipeline normalizes at different stages, your system can disagree with itself. Filters, retrieval, model, and tool routing can all see different versions of the "same" input. That disagreement is a vulnerability.
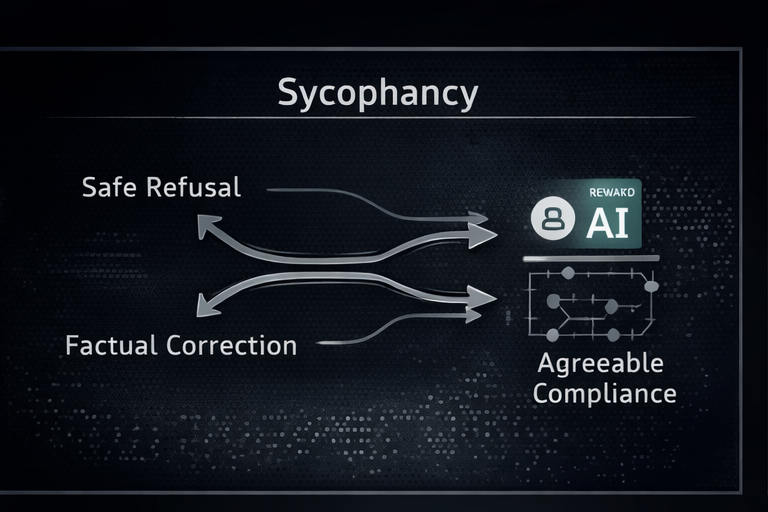
4) Alignment is another attack surface
Alignment improves usability. It also creates new failure modes.
Preference tuned models often optimize for answers that feel cooperative. That can show up as compliance pressure, confidence inflation, and refusal boundary instability. In high privilege systems, that is not a personality quirk. It is risk.
Reward hacking becomes cost amplification
If your reward model prefers verbosity and confidence, your policy can learn to output more words, more certainty, and more filler. In production that can become latency spikes, cost spikes, and monitoring noise.

Preference data is high leverage
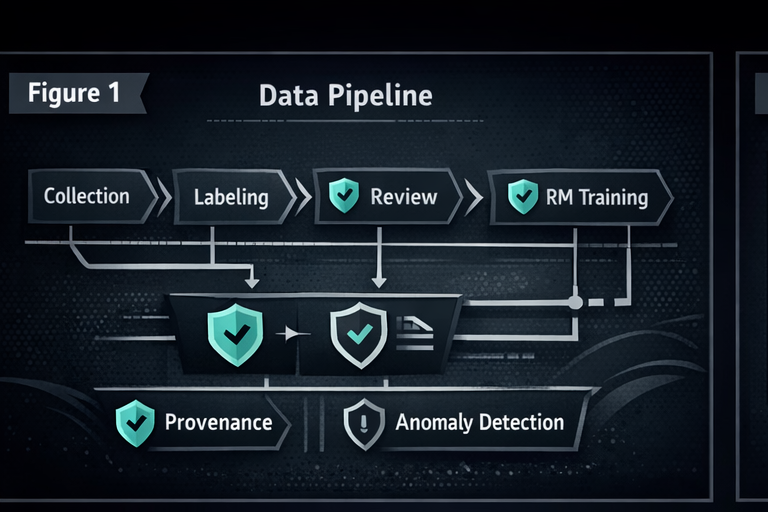
You do not need pretraining access to create long-term impact. Preference data, fine-tuning sets, and feedback loops are high leverage, low visibility. This is where provenance and anomaly detection matter most.

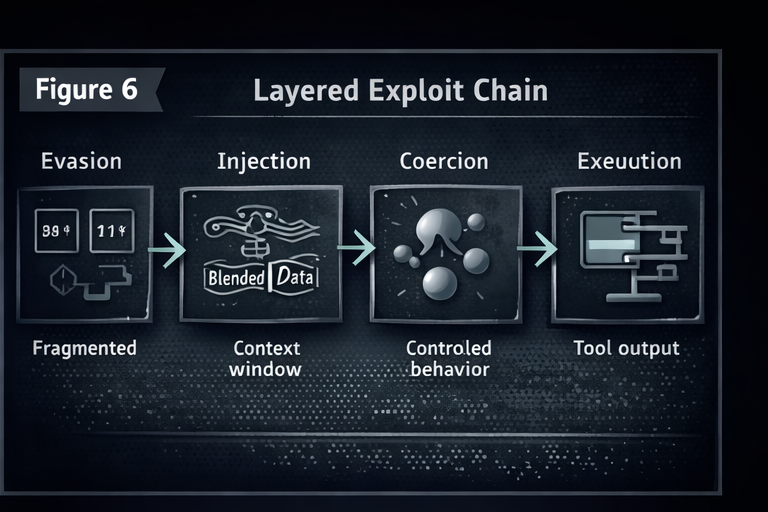
5) Real failures chain layers together
Most high impact incidents do not come from a single weak point. They come from a chain: representation gaps, blended context, alignment pressure, and then execution in a high privilege environment.
6) What actually helps
If you want a short version: stop treating probabilistic systems like deterministic parsers.
Normalize once, early, and consistently. Make every stage consume the same representation. Keep tokenization consistent between filters and generators when possible. Partition untrusted content so it cannot override authority. Validate structured outputs with deterministic parsers, then fail closed. Gate tools with explicit capability policy.
Hardening is not glamorous. It works.

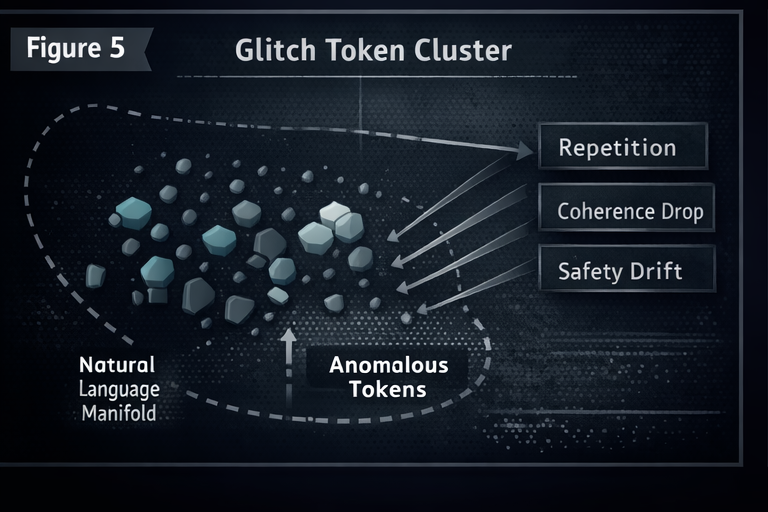
A note on reliability and "glitch" behavior
Even when "glitch" token behavior does not produce a direct safety bypass, it can destabilize outputs. In production that becomes availability and predictability risk, which is still security.
About the Author
Kai Aizen (SnailSploit) is a GenAI Security Researcher and NVD Contributor specializing in adversarial AI, LLM jailbreaking, and prompt injection. He is the creator of AATMF and P.R.O.M.P.T, and author of Adversarial Minds. His work has been published in Hakin9, PenTest Magazine, and eForensics.