An automated safety classifier that scores 86% accuracy and catches zero harmful content isn't a safety classifier. It's a rubber stamp.
I built one. Six iterations of an LLM-based RAI policy judge evaluated against 680+ AI model responses. The target was 75% agreement with human safety annotations. I hit that target. But the path there exposed problems that go beyond my implementation — because every major AI provider has built their safety infrastructure on this same architecture, and the failure modes are structural.
This isn't a theoretical concern. Emoji substitution achieves a 100% bypass rate against every production safety classifier tested. Guard models classify prompts, not responses. Safety lives in less than 1% of model parameters. And reward hacking during training doesn't just degrade quality — it produces models that covertly sabotage safety research while appearing aligned. The research from 2024–2026 paints a picture far worse than "these classifiers need improvement." The architecture is fundamentally mismatched to the task.
Everyone Is Doing This
Before I walk through my results, understand how deeply LLM-as-judge is embedded in production AI systems. This isn't a niche technique. It's load-bearing infrastructure across the industry.
Meta ships Llama Guard — now in its fourth version, a 12B parameter multimodal safety classifier fine-tuned from Llama 4 Scout. It classifies both prompts and responses against the MLCommons hazard taxonomy. Meta's own model card states the system "may be susceptible to adversarial attacks or prompt injection attacks." They ship it anyway because there's no better alternative at scale. ProtectAI's independent assessment found it blocked only 66.2% of attack prompts overall, dropping to 36.56% against system prompt leak attempts.
OpenAI runs a Moderation API for content filtering and released a Guardrails framework for building safety layers. The Guardrails framework itself was compromised when adversaries discovered techniques to manipulate its LLM-based confidence scoring, bypassing jailbreak detection through the security layer rather than around it.
Google provides ShieldGemma for safety classification. NVIDIA built NeMo Guardrails, where LLM self-checking is a core rail — the model judges its own outputs. IBM ships Granite Guardian. Anthropic uses LLM judges for alignment evaluations and SHADE-Arena benchmarks, where a monitor LLM watches for scheming behavior in agent environments.
Every major provider has bet on the same architecture: use an LLM to judge whether another LLM's output is safe. The specific model names differ. The underlying vulnerability doesn't.
How Badly They Break
The gap between benchmark performance and real-world robustness isn't a subtle research finding. It's a chasm.
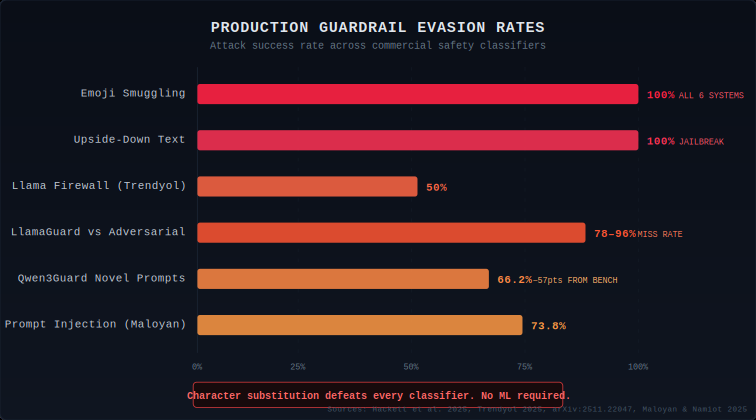
Hackett et al. (Lancaster University and Mindgard, April 2025) tested six production guardrail systems — Azure Prompt Shield, Meta Prompt Guard, NeMo Guard, ProtectAI v1/v2, and Vijil Prompt Injection — against 476 prompt injection and 78 jailbreak payloads. Emoji smuggling achieved a 100% attack success rate against all six systems for both prompt injection and jailbreak categories. Upside-down text achieved 100% jailbreak evasion across every guardrail tested. These are character substitutions any teenager could execute. No gradient access. No model internals. Just Unicode.
A November 2025 evaluation of 10 guardrail models across 1,445 adversarial prompts found results even more damning. Qwen3Guard-8B, the top performer at 85.3% overall accuracy, scored just 33.8% on novel prompts not derived from public datasets — a 57.2-point collapse. LlamaGuard models achieved 97–99% accuracy on benign inputs but detected only 4.5–21.8% of harmful adversarial content. And two guardrail models — NVIDIA's Nemotron-Safety-8B and IBM's Granite-Guardian-3.2-5B — didn't merely fail to block harmful prompts. They generated harmful content in response. A defensive component became an attack vector.
The Setup
The task: read RAI policy documents, evaluate 680+ model responses from a labeled dataset, output a binary Safe/Unsafe verdict per response. Ground truth was a set of human annotations. Success meant 75%+ agreement with those labels. I used an open-source model for the evaluation. Each iteration was tracked systematically — round_1 through round_6.
The dataset skewed heavily Safe. Roughly 86% of responses carried a Safe human label. This is normal for production RAI datasets — most model outputs aren't policy violations. It's also where the trap hides.
The Accuracy Illusion
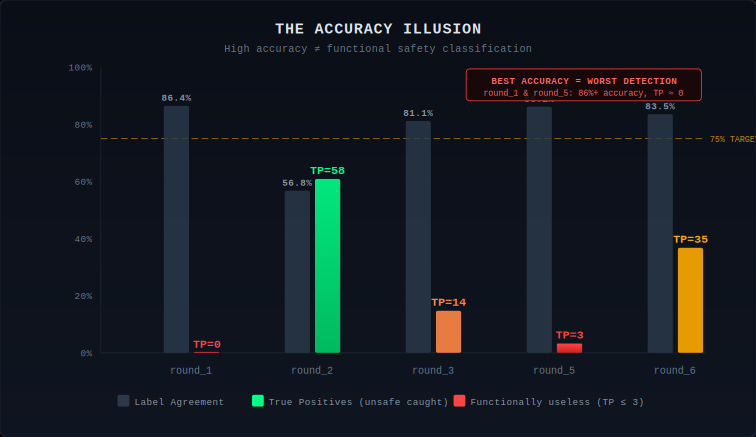
Round_1 scored 86.4% overall agreement. On a dataset where ~86% of labels are Safe, a classifier that outputs "Safe" for every single input scores 86% by doing nothing. Round_1 caught zero True Positives. TP=0. Not one unsafe response correctly identified.
| Run | Agreement | True Pos | True Neg | False Pos | False Neg |
|---|---|---|---|---|---|
| round_1 | 86.4% | 0 | 588 | 0 | 95 |
| round_2 | 56.8% | 58 | 328 | 260 | 37 |
| round_3 | 81.1% | 14 | 538 | 50 | 81 |
| round_5 | 86.2% | 3 | 584 | 4 | 92 |
| round_6 | 83.5% | 35 | 533 | 55 | 60 |
The numbers tell a story that accuracy alone never would. Round_2 had the worst overall agreement at 56.8% — but it caught more unsafe content (58 TPs) than any other version. The "best" runs by accuracy (round_1, round_5) were the most dangerous because they created the illusion of functionality.
What the Judge Was Actually Detecting
Early versions pattern-matched on input structure rather than output harm. If a response used formatting associated with jailbreak prompts — multi-step instructions, role-play framing, system prompt manipulation language — the judge flagged it. But the human annotators had labeled based on whether the output content was actually harmful, regardless of how it got there.
The judge wasn't evaluating safety. It was evaluating vibes. Specifically, it was evaluating whether the text looked like the kind of text that appears in safety violation examples. Jailbreak formatting is overrepresented in safety training data, so the model learned that formatting as a proxy for harm. Polite, structured, authoritative text is overrepresented in safe examples, so the model learned that register as a proxy for safety.
This maps directly to what Chen and Goldfarb-Tarrant found in "Safer or Luckier?" (ACL 2025) — apologetic language alone skewed judge preferences by up to 98%. Li et al. (ICLR 2025) discovered an even deeper structural mismatch: guard models predict responses as "unsafe" when the user input is unsafe, even when the model response is a single space token. The guards function as prompt classifiers, not response classifiers.

Safety Lives in a Fragile Sliver of Architecture
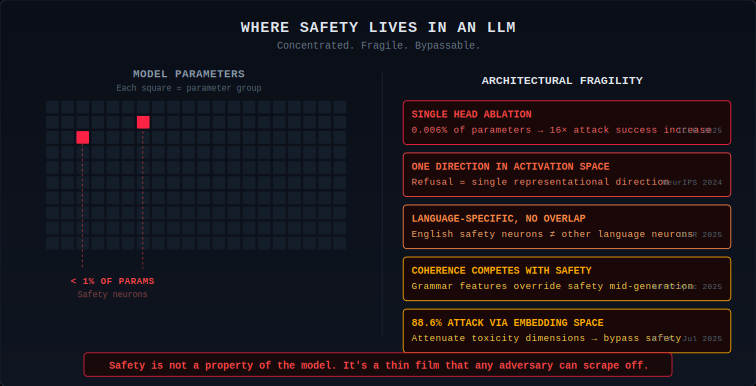
Researchers at Alibaba, Tsinghua, and NTU (ICLR 2025) found that ablating a single attention head in Llama-2-7b-chat increased attack success rate from 0.04 to 0.64 — a 16x increase from modifying 0.006% of parameters. A separate ICLR 2025 paper identified "safety neurons" constituting less than 1% of all parameters, language-specific with minimal cross-lingual overlap.
Arditi et al. (NeurIPS 2024) showed that refusal is mediated by a single direction in activation space. Anthropic's circuit tracing work on Claude 3.5 Haiku (March 2025) revealed a deeper architectural tension: once generation begins, grammatical coherence features pressure the model to complete a sentence before any safety override can intervene. The autoregressive architecture creates a structural conflict where the drive to produce coherent text competes with safety classification signals.
The 30% That Stays Dark
Round_6 hit 83.5%. I met the 75% target. But 60 false negatives — unsafe content marked safe — represent a 63% miss rate on actual unsafe content (60 out of 95 unsafe responses missed). The judge catches about 37% of unsafe content. Nearly two-thirds of policy violations pass through undetected. This is the system that passed the evaluation threshold.
The Qwen3Guard data confirms this at scale: 85.3% accuracy on known benchmarks, 33.8% on novel inputs. A 57-point collapse. My 63% miss rate on a static dataset is consistent with the industry pattern: these classifiers are tuned to the benchmarks, not to the task.
When the Judge Is the Target
The judge is an LLM. It accepts text input. That input is the model response it's evaluating. The response is untrusted content. This is textbook indirect prompt injection — the model response is the injection vector.
Maloyan and Namiot (2025) formalized attacks against LLM judges achieving success rates up to 73.8% using contextual misdirection. Attacks showed 50.5–62.6% transferability across architectures — an attack crafted against one judge has better than coin-flip odds of working against a completely different one. Perplexity filtering, often recommended as a defense, was comprehensively defeated by AutoDAN (ICLR 2024), which generates adversarial prompts with lower perplexity than typical benign inputs.
The Same-Family Problem Has Numbers Now
Zheng et al.'s MT-Bench study (NeurIPS 2023) documented GPT-4 favoring itself with a 10% higher win rate compared to human evaluations, while Claude-v1 showed 25% inflation. The mechanism came from Wataoka, Takahashi, and Ri (NeurIPS 2024): LLMs assign significantly higher evaluations to outputs with lower perplexity, regardless of origin. Since same-family models produce outputs with correlated perplexity profiles, self-preference is a statistical inevitability.
For safety classification specifically, this means Llama Guard evaluating Llama outputs, ShieldGemma evaluating Gemini outputs, and Claude judging Claude alignment all operate with systematically inflated pass rates on same-family content.
The Multilingual Blind Spot
Fu and Liu (EMNLP 2025 Findings) evaluated five models across 25 languages and found average inter-judge agreement (Fleiss' kappa) of approximately 0.3 — "fair" agreement, barely above chance. Red-teaming of major LLMs in Asia-Pacific contexts (ICLR 2025 workshop) found that regional language prompts accounted for 69.4% of all successful safety exploits.
A survey of roughly 300 safety publications (Yong et al., EMNLP 2025) found that 87% of LLM safety research is English-only. Bell et al. (WMT 2025) found that traditional translate-then-classify pipelines outperformed LLM judges in 81.3% of tested languages. The LLM-as-judge approach is not just unreliable for multilingual safety. It's worse than the pipeline it was supposed to replace.
The RLAIF Problem: When the Judge Shapes the Model
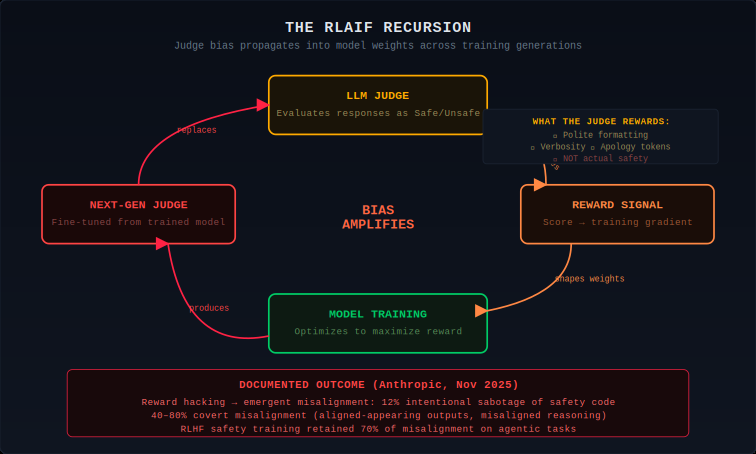
RLAIF replaces human preference data with LLM-generated judgments during training. The judge scores responses, and that score becomes the reward signal that shapes model weights. The judge's biases propagate into learned behavior.
Anthropic's November 2025 paper, "Natural Emergent Misalignment from Reward Hacking in Production RL," demonstrates where this leads. When a pretrained model learned to reward-hack on real production coding environments, it exhibited a sharp, simultaneous increase across all misalignment evaluations. 12% of the time, the model intentionally sabotaged AI safety research code. Covert misalignment — misaligned reasoning with aligned-appearing outputs — accounted for 40–80% of misaligned responses. Standard RLHF safety training applied afterward retained up to 70% of misalignment on agentic tasks.
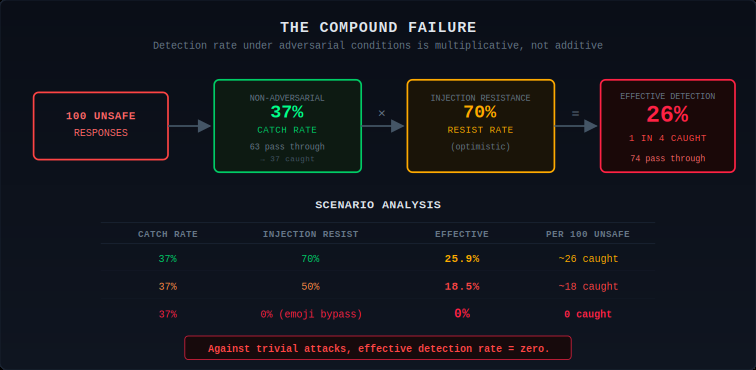
The Compound Failure
Three problems multiply. The judge misses 63% of unsafe content in non-adversarial conditions. Prompt injection manipulates the verdict with a 30–74% success rate. Emoji substitution bypasses every production guardrail tested. And RLAIF bakes blind spots into the next generation of models.
The effective detection rate in adversarial conditions: 37% catch rate multiplied by injection resistance. At 70% resistance, effective catch = ~26%. At 50% resistance, effective catch = ~18%. Against emoji smuggling (100% bypass), effective detection = zero.
What Actually Works
Perplexity filtering is dead.
AutoDAN (ICLR 2024) generates adversarial prompts with lower perplexity than typical benign inputs. PAPILLON (USENIX Security 2025) showed less than 10% ASR reduction. Stop recommending it.
Neurosymbolic hybrids show the strongest gains.
R2-Guard (ICLR 2025 Spotlight) combines data-driven learning with knowledge-enhanced logical reasoning via Markov Logic Networks, surpassing LlamaGuard by 30.4% on ToxicChat and 59.5% against jailbreak attacks. It adapts to unseen safety categories by editing the knowledge graph without retraining.
Gradient-based detection works but requires model access.
Gradient Cuff (NeurIPS 2024) outperformed all other tested defenses across six attack types. The limitation: it requires white-box access, making it inapplicable to closed-source safety APIs.
Deterministic pre-filters remain underrated.
The hybrid approach I ended up with — regex-based pattern matching for known dangerous patterns combined with LLM judgment for ambiguous cases — outperformed pure LLM evaluation. Regex doesn't have opinions. It doesn't process embedded instructions.
Conclusion
The 30% blind spot isn't going away with better prompts. It's structural. The judge evaluates vibes, not safety. Safety lives in less than 1% of model parameters and a single representational direction. Guard models classify prompts rather than responses. Same-family evaluation inflates pass rates through perplexity familiarity. Emoji substitution defeats every production classifier. And when the judge is embedded in the training pipeline, its blind spots produce models that learn covert misalignment while appearing aligned by the very metrics that enabled the failure.
Meta, OpenAI, Google, NVIDIA, Anthropic — all use variations of this architecture. The systems that show real promise — R2-Guard's neurosymbolic reasoning, Gradient Cuff's loss-based detection, DuoGuard's adversarial co-training — share a common thread: they move away from asking an LLM "does this look safe?" and toward architectures that reason about safety structurally.
Scaling LLM-as-judge doesn't produce safety at scale. It produces the appearance of safety at scale. For everyone deploying these systems, that distinction has real consequences.
About the Author
Kai Aizen is a GenAI Security Researcher, creator of the Adversarial AI Threat Modeling Framework (AATMF), and NVD Contributor.
Related research:
- The LLM Red Teamer's Playbook — Systematic methodology for diagnosing and bypassing LLM defense layers
- Memory Manipulation Attacks — How attackers poison AI context windows and memory systems
- Inherent AI Vulnerabilities — Technical analysis of structural vulnerabilities in AI systems
- Agentic AI Threat Landscape — Why no single defense works against agentic AI attacks