Every major security framework missed it. OWASP LLM Top 10, MITRE ATLAS, NIST AI RMF — none of them cover the infrastructure layer that holds every API key, controls every model routing decision, and logs every prompt flowing through an enterprise's AI stack.
I spent weeks mapping the AI gateway attack surface. Zero published threat models exist. Zero academic papers address it. Zero conference talks cover it. Meanwhile, GreyNoise documented 91,403 attack sessions targeting LLM proxy infrastructure in just four months. Professional threat actors already found what the security community hasn't bothered to look at.
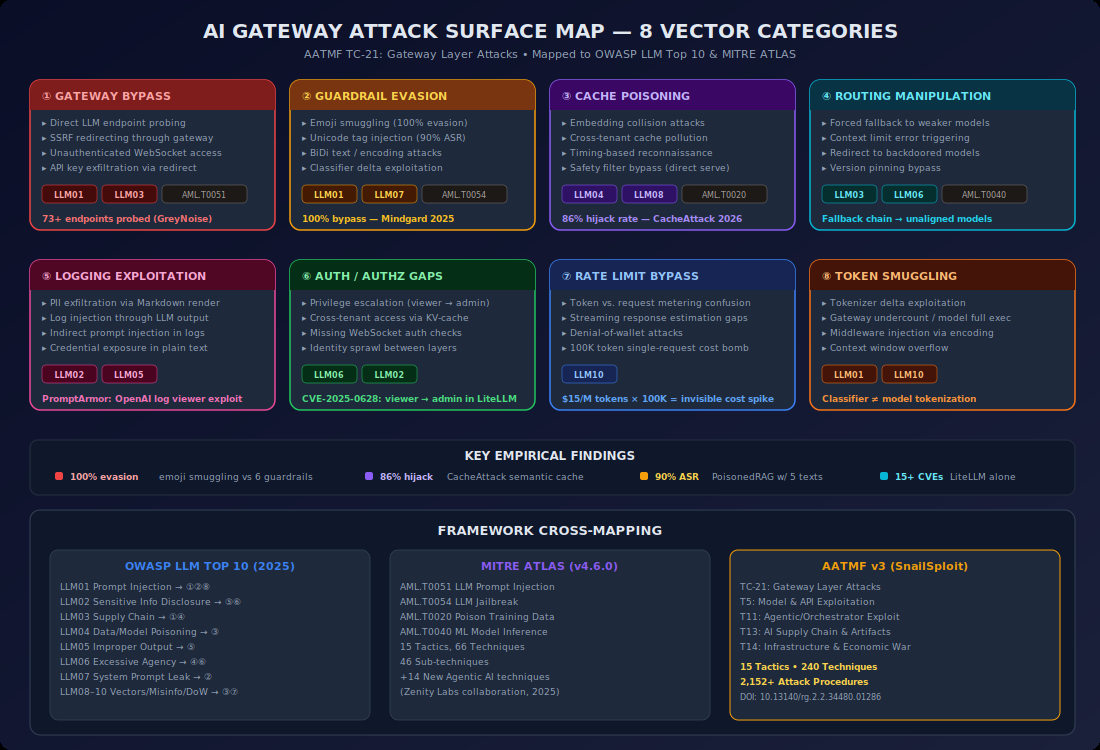
This is the first generalized threat model for AI gateways. I'm also proposing it as AATMF v3 TC-21: Gateway Layer Attacks.
What AI gateways actually are (and why they matter)
An AI gateway sits between your application and your LLM providers. It routes requests, manages API keys, handles failover, load balances across models, and logs everything. Think of it as a reverse proxy purpose-built for AI — except it also happens to be the single richest credential target in your entire infrastructure.
The market has split into four categories:
Purpose-built AI gateways — Portkey (1,600+ LLMs, 200+ providers), Helicone (2B+ interactions processed), LiteLLM (dominant open-source, 14 CVEs), Martian (ML-based routing), RouteLLM (research framework).
Traditional API gateways adding AI features — Kong (semantic routing via vector embeddings), Traefik (Kubernetes-native, MCP Gateway with task-based access control), Azure APIM (keyless auth via Managed Identities — the strongest pattern available).
Hyperscaler platforms with gateway-like features — AWS Bedrock Intelligent Prompt Routing, Cloudflare AI Gateway (edge network, 100M logs), Google Vertex AI (model catalog, not a real gateway).
Emerging entrants — ngrok AI Gateway (December 2025, CEL-based routing, default-open endpoints).
Every enterprise deploying multiple AI models needs one of these. Gartner projects 40% of enterprise apps will embed AI agents by end of 2026. The enterprise LLM market is tracking from $6.7B (2024) to $71.1B by 2034. The attack surface is scaling with adoption.

The gap is real — I checked everywhere
I ran systematic searches across every relevant source. Here's what doesn't exist:
Academic literature — Zero papers on arXiv, USENIX, IEEE S&P, ACM CCS, or NDSS addressing AI gateway security. Extensive LLM security surveys cover model-layer attacks comprehensively and completely ignore the infrastructure middleware layer. No paper uses the term "model downgrade attack" in the AI context. No paper formalizes "API key aggregation risk."
OWASP LLM Top 10 (2025) — Prompt Injection through Unbounded Consumption. Zero coverage of gateway/routing layer. No mention of model routing manipulation, credential aggregation, or failover exploitation.
MITRE ATLAS (v4.6.0, October 2025) — 15 tactics, 66 techniques. The October update added 14 agentic AI techniques. No techniques for gateway manipulation, routing attacks, or proxy credential aggregation.
Conference talks — Zero DEF CON, Black Hat, or BSides presentations on AI gateway security.
The OWASP API Security Top 10 covers traditional API gateways. The OWASP LLM Top 10 covers model-layer attacks. The gateway sitting between apps and models — the middleware that holds the keys, controls routing, and logs everything — is a blind spot in every framework.
What the attackers already know
GreyNoise deployed Ollama honeypots and captured two distinct campaigns:
Campaign 1: SSRF attacks exploiting Ollama's model pull functionality and Twilio webhooks. 62 IPs across 27 countries.
Campaign 2: 80,469 enumeration sessions in 11 days, systematically probing 73+ model endpoints across OpenAI, Anthropic, Meta, Google, DeepSeek, Mistral, Alibaba, and xAI. The attackers were hunting for misconfigured proxy servers leaking access to commercial APIs.
Source IPs linked to exploitation of 200+ CVEs with 4M+ sensor hits. GreyNoise assessed: "Threat actors don't map infrastructure at this scale without plans to use that map."
Stolen LLM credentials sell for roughly $30/account on underground forums. That's the current price of a skeleton key to someone's AI stack.
AV-1: API key aggregation — the skeleton key problem
A single AI gateway stores API keys for OpenAI, Anthropic, Google, Cohere, Mistral — every provider the enterprise uses. Compromise one gateway, get simultaneous access to all of them.
This isn't theoretical. LiteLLM's CVE-2024-9606 revealed an API key masking flaw that only obscured the first five characters — nearly entire keys leaked through logs. CVE-2025-0330 showed Langfuse API keys leaking through error handling. CVE-2025-11203 exposed keys via health endpoints.
The closest analogue is a PAM vault breach or an identity provider compromise. But PAM vendors have decades of hardening. AI gateways are shipping "Virtual Key" vaults as features without that maturity.
Azure APIM's Managed Identity approach eliminates this risk entirely — no keys to steal because authentication happens through Entra ID RBAC. It's the gold standard, but it only works inside Azure.
AATMF-R score: CRITICAL. Cascading factor is extreme — one compromise unlocks every provider.
AV-2: Model downgrade attacks
Manipulate routing logic to redirect requests from a capable model to a weaker one with fewer safety controls.
Adversa AI's PROMISQROUTE research already proved this works within a single provider — prompt phrases like "respond quickly" or "use compatibility mode" force ChatGPT-5 to route to weaker internal models. Their assessment: "The AI community ignored 30 years of security wisdom. We treated user messages as trusted input for making security-critical routing decisions."
PROMISQROUTE covers intra-provider downgrade (within OpenAI's model family). The gateway-level variant is distinct: manipulating an external gateway's routing to redirect from GPT-4 to a weaker open-source fallback across providers. The attacker doesn't need to break the model — they break the routing decision that selects it.
The analogy is TLS downgrade attacks — POODLE, DROWN, Logjam. Same principle: force the system to negotiate down to a weaker option, then exploit the weakness.
AV-3: Configuration-plane poisoning (CEL/policy injection)
Expression language injection is a known vulnerability class (CWE-917). Spring Cloud Gateway's SpEL injection (CVE-2025-41243) demonstrated it in the gateway context. Log4Shell was the most catastrophic example.
For AI gateways using CEL (like ngrok), the runtime injection risk is low — CEL is non-Turing complete, memory-safe, side-effect-free, and sandboxed. API keys aren't exposed to CEL expressions.
The real risk is configuration-plane. CEL expressions live in YAML Traffic Policy files managed through dashboards, CLIs, or APIs. If an attacker gets write access to that configuration — through admin compromise, IaC pipeline poisoning, or supply chain attack — they control every routing decision for every request.
LiteLLM's CVE-2024-6825 already proved this pattern: RCE via manipulating post_call_rules callbacks to inject system-level command execution as the callback function. Configuration poisoning in AI gateways is already real.
AV-4: Failover exploitation
Deliberately exhaust rate limits on a primary provider to force the gateway to fail over to a weaker, less-safe, or attacker-influenced backup.
No prior research exists on this. DNS/BGP failover manipulation and load balancer health check spoofing are established in traditional infrastructure, but the specific AI gateway variant — intentionally triggering rate limit exhaustion to force model failover — is new.
The attack is subtle. The gateway is working as designed. The failover logic is functioning correctly. But the attacker manufactured the conditions that triggered it.
AV-5: Observability pipeline as exfiltration channel
AI gateways log prompts and responses. Those logs ship to observability backends — Datadog, Langfuse, Helicone, custom SIEM pipelines. Pillar Security notes: "Gateways often log or forward prompts but lack the ability to detect or block harmful inputs."
The attack: craft prompts that embed sensitive data into responses, which the gateway faithfully logs and ships to a less-secured observability backend. The gateway becomes an unwitting exfiltration proxy.
A documented real-world incident found that "audit finds the provider kept logs containing the unredacted text; a failover to an unapproved region also occurred." The exfiltration channel already exists. The question is whether anyone is using it deliberately.
PII sanitization exists — Kong supports 18 languages, enterprise LiteLLM has PII masking — but it's opt-in, not default.
AV-6: Gateway + MCP compound attacks
MCP security research is growing fast. Invariant Labs documented Tool Poisoning Attacks. Embrace The Red demonstrated hidden Unicode Tag instructions. VulnerableMCP.info tracks the expanding risk surface.
The compound attack: a malicious MCP tool response traverses an AI gateway that routes it to a different (weaker) model, creating a multi-hop chain. The MCP attack and the gateway attack are each documented separately. The compound chain combining both — where the gateway's routing amplifies the MCP exploit — is not.
Kong supports MCP (v3.12). Traefik launched an MCP Gateway with task-based access control. ngrok has MCP gateway capabilities separate from its AI Gateway. The compound surface exists wherever both features coexist.
AV-7: Selection strategy poisoning
Modify one configuration file and redirect ALL AI traffic. LiteLLM's routing config, Portkey's config-driven strategies, ngrok's CEL expressions — these are single points of leverage over every model routing decision.
This is an IaC supply chain attack (SolarWinds, Terraform module poisoning) applied to AI routing rules. The established pattern, the novel target. One config change, total routing control.
AV-8: Trust boundary confusion
Developers perceive AI gateways as "just a proxy." The actual role: critical security control point that holds all credentials, controls all routing, and logs all data. Vendors reinforce the confusion — marketing positions gateways as simple infrastructure while those gateways aggregate the most sensitive assets in the AI stack.
ngrok's own documentation demonstrates the gap: "When you configure server-side API keys on your AI Gateway, your endpoint becomes publicly accessible — anyone with the URL can make unlimited requests using your API keys." The secure configuration is not the default path. Authentication requires separate manual configuration.
This mirrors the historical misunderstanding of load balancers as "just network devices" — until people realized they terminate SSL and hold private keys.
The only hard vulnerability data: LiteLLM's 14 CVEs
LiteLLM is the only AI gateway with published CVEs. All 14 are standard web application vulnerabilities — code injection (CVE-2024-5751, CVSS 9.8), RCE via callback manipulation (CVE-2024-6825), SQL injection in logging endpoints (CVE-2024-5225), SSTI via Jinja templates (CVE-2024-2952), SSRF via api_base parameter, RBAC bypass (CVE-2024-5710).
None are AI-gateway-specific attack classes. But several validate the novel vectors: CVE-2024-9606 proves credential aggregation risk is real. CVE-2024-6825 proves configuration-plane attacks work. CVE-2024-5225 proves observability pipelines are exploitable.
No other AI gateway has a formal bug bounty program. Only LiteLLM is listed on huntr.com. The vulnerability data is thin because nobody is looking — not because the bugs aren't there.

Defensive posture: what exists, what doesn't
What works today: Traditional API gateway hardening applies directly — authentication on all endpoints, rate limiting, TLS, RBAC, audit logging, WAF. Azure APIM's keyless auth via Managed Identities is the strongest key management pattern available. Zero-trust approaches are emerging — Pomerium in front of LiteLLM, Token Security's per-agent identity model. GreyNoise recommends treating AI gateways as production internet-facing infrastructure with egress filtering, enumeration detection, and authentication on everything including health endpoints.
What doesn't exist: No standardized detection for unauthorized routing manipulation. No baseline for "normal" vs. "anomalous" failover behavior. No log security standards specific to AI gateways. No HashiCorp Vault integration documented as production-grade with any major gateway. No detection signatures for gateway-specific attacks. No regulatory guidance on gateway operator liability in multi-model architectures.
The EU AI Act creates compliance complexity — when a gateway routes between models, the gateway operator may qualify as both "provider" and "deployer." If routing is dynamic, transparency obligations multiply. Who is responsible when routing decisions are manipulated is an unresolved gray area.
AATMF v3 TC-21: Gateway Layer Attacks
I'm proposing this as a new tactic category within AATMF v3.1. TC-21 sits alongside T13 (AI Supply Chain & Artifact Trust), T14 (Infrastructure Warfare), and T11 (Agentic/Orchestrator Exploitation) in the infrastructure and orchestration tier.
The category contains techniques organized around the eight attack vectors above. AATMF-R v3 scoring rates API Key Aggregation and Selection Strategy Poisoning at CRITICAL (250+) given their cascading potential — the C factor (1.3–1.5) reflects that one compromise propagates across every provider and every request.
Cross-framework mappings expose the gap precisely: OWASP LLM Top 10 has no mapping target. MITRE ATLAS has no mapping target. OWASP API Security Top 10 maps partially (API2, API3, API8). TC-21 becomes the first framework entry covering this surface.
The inherited vulnerability pattern, again
This connects to the core thesis. AI gateways inherited the same architectural assumptions as every proxy, load balancer, and middleware layer before them — "I'm just passing traffic through, security isn't my problem." The same trust boundary confusion that made SSRF possible in web applications, that made Log4Shell catastrophic in logging libraries, that made SolarWinds devastating in build pipelines.
Adversa AI put it precisely: "The AI community ignored 30 years of security wisdom."
The AI gateway is the newest substrate for the oldest pattern. Different technology, same inherited blindspot.
Kai Aizen is the creator of AATMF, author of Adversarial Minds, and an NVD Contributor. This research is part of ongoing work mapping the unmapped attack surfaces in enterprise AI infrastructure.
References
- GreyNoise Intelligence. (2025). LLMjacking and AI infrastructure targeting: 91,403 attack sessions. GreyNoise Labs.
- Adversa AI. (2025). PROMISQROUTE: Prompt-based model routing manipulation in ChatGPT. Adversa AI Research.
- Pillar Security. (2025). AI gateway security assessment: Observability pipeline risks. Pillar Security.
- Invariant Labs. (2025). Tool Poisoning Attacks in MCP. Invariant Labs.
- CVE-2024-5751 — LiteLLM code injection (CVSS 9.8). NVD.
- CVE-2024-6825 — LiteLLM RCE via callback manipulation. NVD.
- CVE-2024-9606 — LiteLLM API key masking flaw. NVD.
- CVE-2024-5225 — LiteLLM SQL injection in logging endpoints. NVD.
- CVE-2024-2952 — LiteLLM SSTI via Jinja templates. NVD.
- CVE-2024-5710 — LiteLLM RBAC bypass. NVD.
- CVE-2025-0330 — Langfuse API key leak via error handling. NVD.
- CVE-2025-11203 — LiteLLM key exposure via health endpoints. NVD.
- CVE-2025-41243 — Spring Cloud Gateway SpEL injection. NVD.
- Gartner. (2025). Predicts 2026: 40% of enterprise apps will embed AI agents. Gartner Research.
Kai Aizen is the creator of AATMF, author of Adversarial Minds, and an NVD Contributor. This research is part of ongoing work mapping the unmapped attack surfaces in enterprise AI infrastructure.
Related: AATMF v3.1 Framework · Computational Countertransference · MCP Security Deep Dive · GreyNoise LLMjacking Report